Performing high availability upgrades for Auto Scaling Groups in AWS
Performing high availability (HA) upgrades for Auto Scaling Groups (ASGs) in AWS requires careful planning and execution to ensure continuous service availability. Because Auto Scaling Groups have different configuration options, you have multiple approaches. This article will cover a specific strategy for zero downtime during the upgrade process.
For help implementing this, hop on a call with our sales team so they can learn more about the solution you need.
Understanding the Challenge
Auto Scaling Groups have an Instance Refresh feature that automatically cycles in new EC2 instances. This can be a quick and easy way to roll out a new version update or apply a configuration change, such as upsizing the EC2 instance type.
Since Instance Refresh is fully automated, you must test the process fully in a staging environment to ensure no issues arise. Suppose instead you want to roll out a version upgrade or a minor configuration change directly to Production. In that case, you should take a more manual approach to verify that everything is working every step of the way.
This article covers an alternate approach to Instance Refresh. You’ll use a combination of Warm Pools and the ASG Detach lifecycle state, which are tools to help you take manual control of the rollout process.
Warm Pools
Auto Scaling Groups have a Warm Pool feature that lets you spin up incoming EC2 instances in a staging area that does not receive Load Balancer traffic. This feature was initially intended to reduce latency when scaling out by letting you pre-warm incoming EC2 instances. However, you can also use this feature to test your EC2 instances before putting them in service.
For example, let’s say you have an application that takes several minutes to initialize. You may want to verify the server’s stability before sending Production traffic. Or, let’s say you are performing a version upgrade. You may want to rule out compatibility issues with the new version before routing traffic to the new instances.
Let’s walk through a hypothetical HA upgrade to demonstrate Warm Pools. The diagram starts off with an Auto Scaling Group behind a Network Load Balancer.
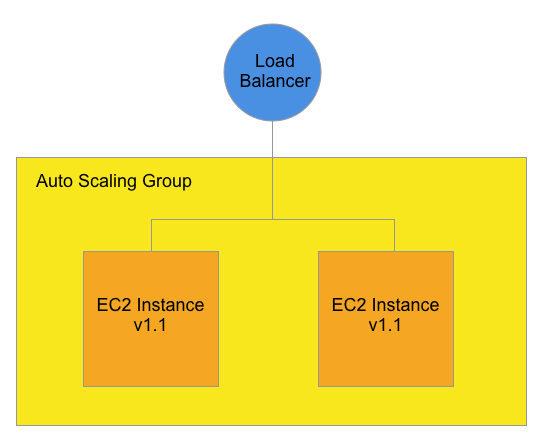
In this diagram, two EC2 instances receive Production traffic. Each EC2 instance has an application running version 1.1.
The following diagram shows what would happen if we created a Warm Pool.
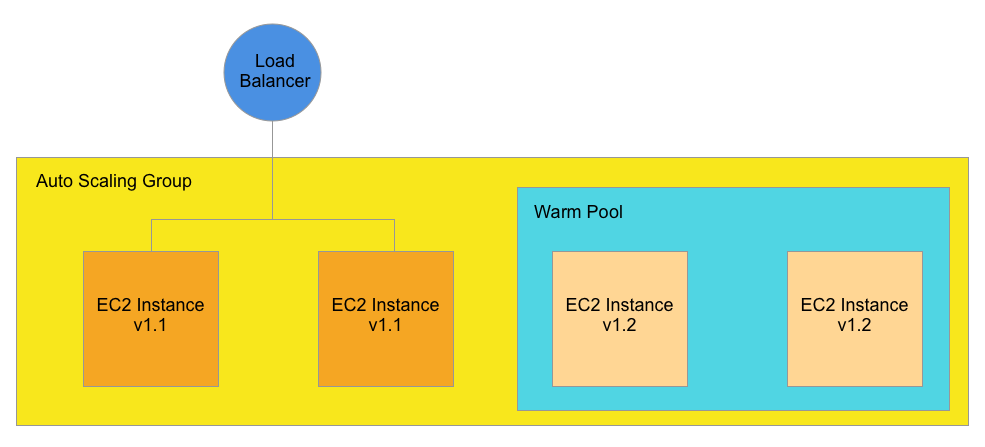
In this diagram, a Warm Pool is created within the Auto Scaling Group. The Warm Pool spins up two additional EC2 instances running the newer version 1.2 (assuming that the Launch Template points to this version).
It’s important to note that the Load Balancer is not yet sending any traffic to the EC2 instances in the Warm Pool. This allows you to deploy, test, and verify incoming instances without impacting Production.
When you are ready to promote the Warm Pool instances to Production, increase the Desired Capacity on the ASG.
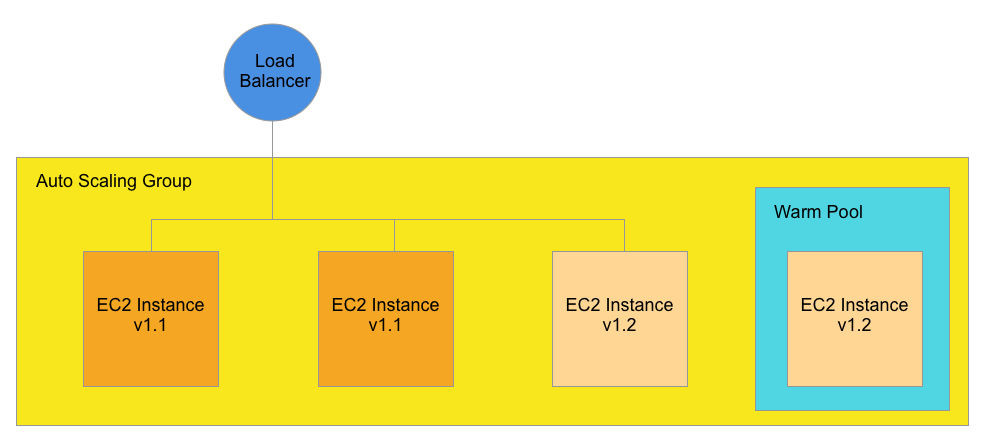
In this Diagram, the Desired Capacity on the ASG is increased from 2 to 3. Instead of spinning up a new EC2 instance, one of the Warm Pool instances is drafted into service.
In this example, the Load Balancer sends traffic to one of the new v1.2 instances and the two original v1.1 instances. One instance still remains in the Warm Pool.
As you continue increasing the Desired Capacity, the ASG will continue drafting instances from the Warm Pool. The following Diagram shows the Desired Capacity increased from 3 to 4:
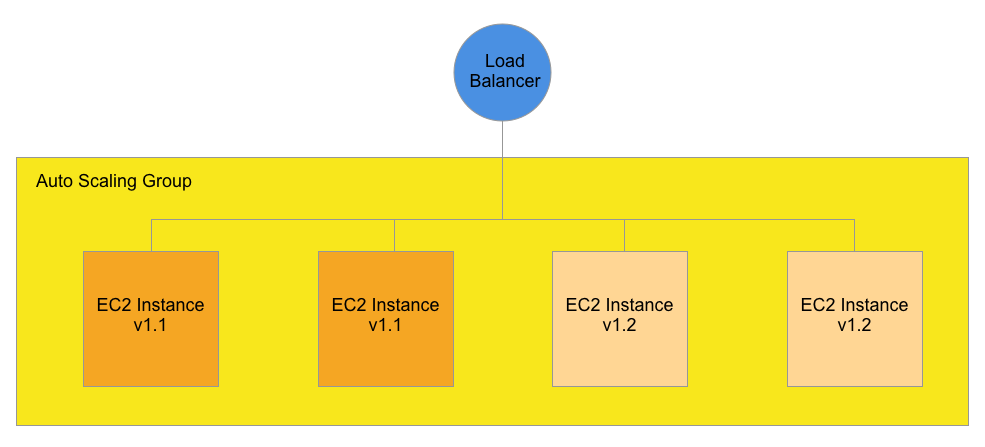
In this example, all 4 EC2 instances receive Production traffic, and nothing remains in the Warm Pool. Note: Remember to delete the Warm Pool; otherwise, it will be replenished with two more instances.
We are over capacity, so the next step is to remove the original v1.1 instances.
Detaching Instances from the ASG
The ASG still contains the original v1.1 instances. So we want to remove them to finish this version upgrade.
The most straightforward approach is to reduce the Desired Capacity from 4 to 2. Theoretically, the oldest EC2 instances are removed, which is what we want. Also, the ASG should hopefully be smart enough to drain connections before terminating the instances to avoid intermittent service outages.
Since our priority is zero downtime, we want to eliminate guesswork and take manual control of the process. To accomplish this, we use the ASG Detach feature. This allows us to stop sending traffic to instances before terminating them. It also gives us control over which specific instance we want to remove.
Auto Scaling Groups have several Lifecycle stages. For example, InService means the instance can receive Load Balancer traffic.
There are two other Lifecycle stages we are interested in:
- StandBy: The instance stops receiving Load Balancer traffic. This is intended to temporarily take a production instance out of service for (a) troubleshooting or (b) to make a configuration change.
- Detached: The instance also stops receiving Load Balancer traffic. However, this is intended for permanently removing an instance from the ASG.
See the official AWS documentation regarding ASG Lifecycle stages.
We want to use the Detach operation to stop sending Load Balancer traffic to an instance. The following diagram demonstrates this idea:
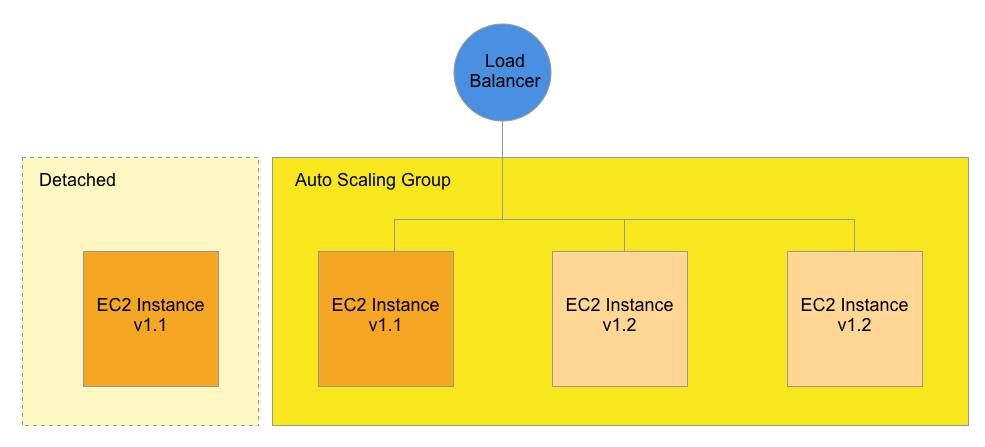
In this example, we Detach one of the v1.1 EC2 instances from the Auto Scaling Group so that it becomes a standalone instance.
It’s important to note that there is no service disruption when Detaching an EC2 instance. The connections from the Load Balancer to the instance are drained over time, and the instance becomes fully Detached when traffic stops flowing to it. Note: the Detached instance is still running.
You can repeat the Detach process on the remaining v1.1 instance:
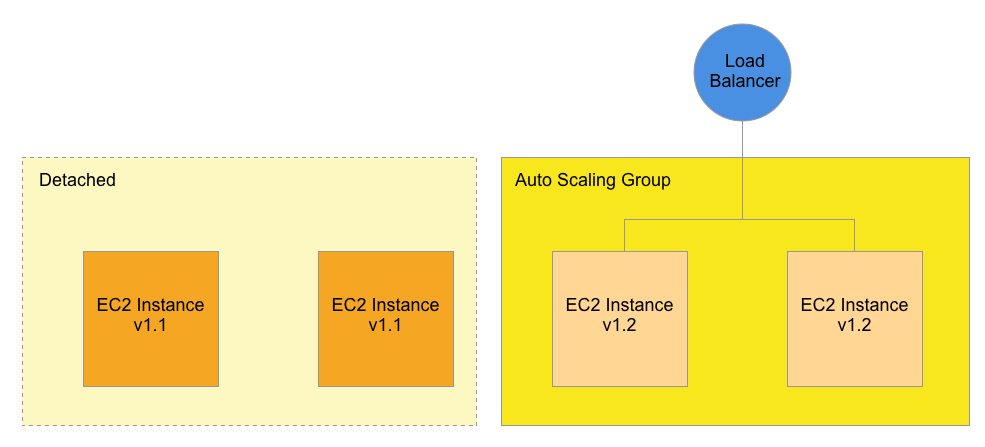
At this point, the Auto Scaling Group only contains the new v1.2 instances. The older v1.1 instances are still running, but they no longer receive any Load Balancer traffic.
Now that the old v1.1 instances are disconnected, they can be safely terminated without any impact to Production.
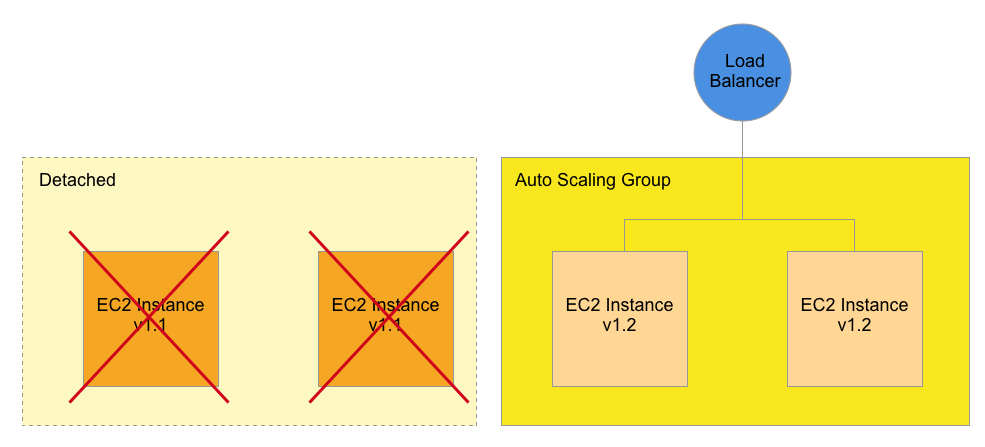
In this Diagram, the old v1.1 instances are terminated, and the ASG and Load Balancer are unaffected. We end up with the desired result, which is to upgrade to v1.2 with zero downtime.
Conclusion
The approach outlined in this article provides a controlled, reliable method for performing zero-downtime upgrades to your Auto Scaling Groups in AWS. By leveraging Warm Pools and the ASG Detach lifecycle state, you gain manual control over the entire upgrade process while maintaining continuous service availability.
This method offers several key advantages over fully automated solutions like Instance Refresh:
- Verification at each step: You can thoroughly test new instances before they receive production traffic
- Controlled rollout pace: The upgrade proceeds only as quickly as you allow it to
- Enhanced safety: Connection draining ensures no requests are interrupted during instance transitions
- Targeted instance management: You decide precisely which instances to remove, rather than relying on ASG’s termination policies
- Easy rollback capabilities: If issues arise, you can pause the process before further affecting Production
While this approach requires more manual intervention than automated solutions, the additional control is invaluable during critical production upgrades where verification at each step is essential. Instance Refresh may still be the more efficient option for less critical environments or well-tested changes.
Hopefully, this article helps you conceptually understand how to perform HA upgrades with zero downtime. For a real-life example with technical step-by-step instructions, check out this knowledge-base article. You can also book a call with our sales team and learn about getting customized deployment help from our experts.