
Cloud computing has made disaster recovery better and cheaper. Here’s what you need to know about how to integrate the cloud into your disaster recovery plan.
A disaster can strike at any time, disrupting the delivery of your software applications to your customers and your business’ continuity.
Whether it’s due to an outage in your network, a natural disaster, or a bug in your code, downtime can bring your business to a halt, leading to lost time, customers, and revenue.
That’s why having a disaster recovery (DR) plan is so important.
Traditional DR methods are extremely expensive and time-consuming.
But with cloud computing, creating the necessary backup infrastructure to ensure a quick and efficient recovery is easier and more cost-effective than ever.
Let’s take a look at the old-school way of disaster recovery, how cloud-based DR compares, and the steps you can take to integrate the cloud into your DR plan.

Image courtesy of MaxPixel
How disaster recovery used to be done
Traditional disaster recovery approaches entailed off-site duplication of data and infrastructure. So if something catastrophic were to happen to your primary data center, you could quickly switch to the backup data center to get critical applications up and running again.
This duplicate data center, of course, comes with duplicate work.
This may include at minimum:
-
- Facilities and real estate to house the IT infrastructure
- Management and security personnel for these facilities
- Enough server capacity to store all data and meet the scaling requirements of your applications
- Support staff for maintaining the infrastructure
- Internet connectivity with enough bandwidth to power your applications
- Network infrastructure such as firewalls, routers, switches, and load balancers
That’s a lot of stuff to manage and a lot of money to spend. And the data center is there just for backup and won’t be used most of the time.
Actually, your hope is that your backup data center never gets used at all.
How wasteful is that?
Benefits of using the cloud for DR
More and more companies are leveraging the cloud for disaster recovery.
According to Zetta, 50% of companies are using cloud-based DR solutions, and backup is the 2nd most widely-used application of cloud computing, with disaster recovery coming in 7th.

That’s because cloud computing provides so many benefits over traditional disaster recovery approaches. Here are some of these benefits.
Saves time and money
All that stuff that you had to build and manage to prepare for a disaster – the second data center facility, the additional staff, servers, and other infrastructure – all goes away.
Cloud providers only charge you when services are being used. So instead of incurring all of the aforementioned costs required to build and maintain duplicate data centers, you’ll pay only a fraction of that when backing up your applications in the cloud.
And if disaster doesn’t ever strike, your costs will be even lower.
You have many more options for where to back up your mission-critical data
When using the cloud for DR, you can select which of your cloud provider’s data centers will be used to back up your application.
The backup location should be geographically far away from your data center to reduce the chance that you’ll lose both the live application and backup copy in the same incident.
Let’s pretend for a moment that your company operates security software, your headquarters are in Berlin, and most of your customers are in Germany. So you’ve built a data center close to your offices to run your software.
If you’ve built a backup data center, it may likely be located in another part of Germany a couple of hundred miles away, since that’s where you know how to do business, your customers are in proximity, and it’s close enough to maintain and manage.
But what happens if a huge freak storm covers the entire country and knocks out both of your data centers?
If you used Amazon Web Services for DR, you could choose to back up your application in their data center in Ireland, or even further away in Mumbai or Singapore.
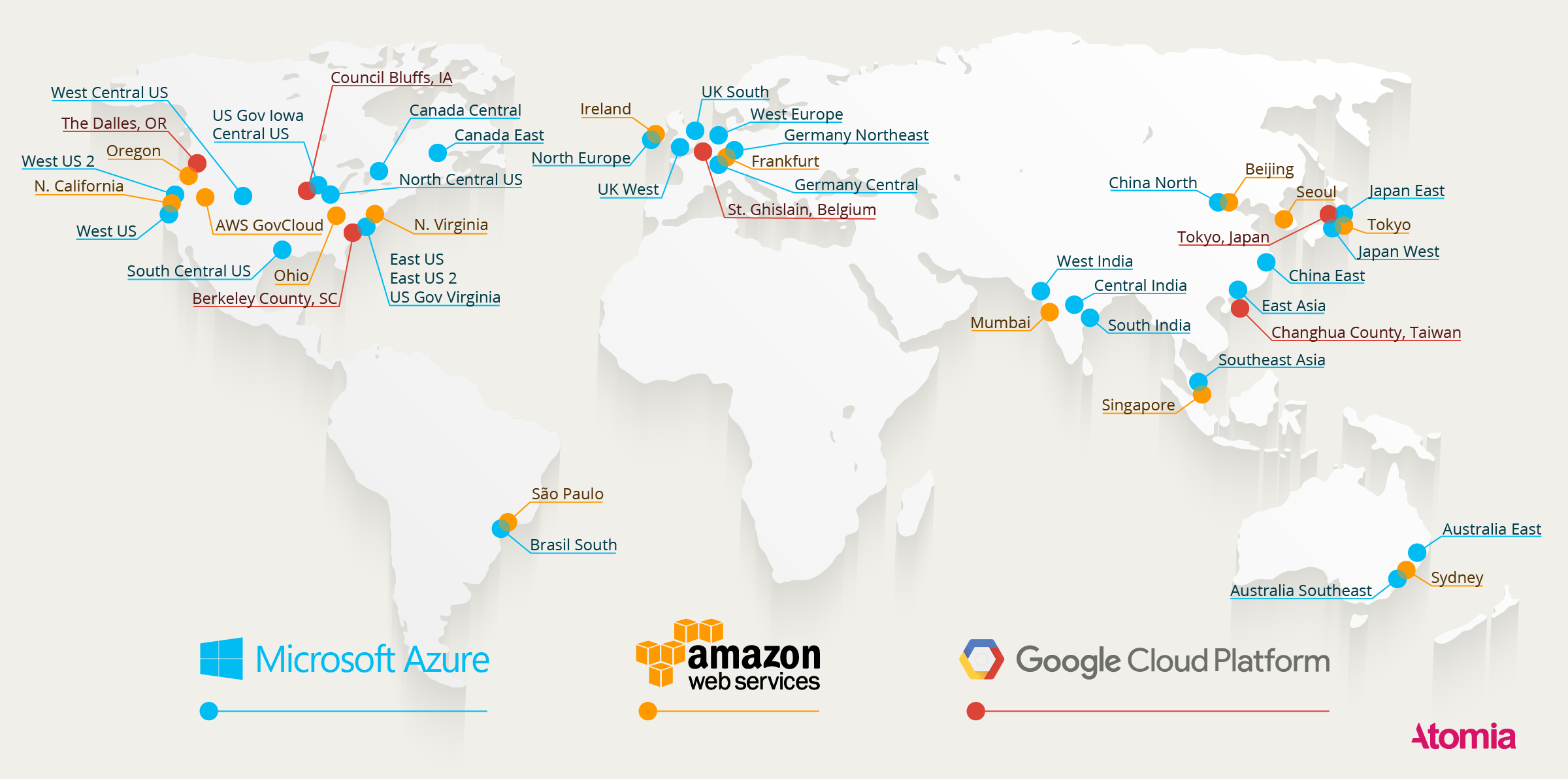
You may even want to use multiple cloud providers in different locations to back up your applications. (More on this later).
In the cloud, you’ll have many options of where you can house your backup, which will increase the resiliency of your applications by avoiding regional disasters.
Easily implemented with high reliability
Disaster recovery solutions are relatively easy to set up in the cloud, especially compared to setting up your own duplicate data center.
You don’t have to purchase and deploy backup servers, drives, and disks.
Rather, you can easily and instantly deploy a cloud storage solution such as Amazon S3 to back up your data, or even tier your backup with longer-term data storage solutions like Amazon Glacier to lower costs even more.
And it’s extremely easy to restore your infrastructure quickly if your app is backed up in the cloud.
There’s no more dealing with transportation and restoration of backup tapes to get your application up and running again. When using the cloud for DR, you can access all of your data through the internet much more quickly and easily.
Disaster recovery is just much easier in the cloud.
Scalability
Cloud services can be easily scaled up to meet demand as needed.
In the traditional DR scenario, you had to make sure that you had enough server capacity in your duplicate data center to meet demand.
And if you didn’t, app performance would be slow and sluggish.
With the cloud, scaling capacity is simple, quick, and more cost effective, ensuring that your customers will have a great user experience even in the case of a disaster.
Designing a DR plan in the cloud
Now you know the benefits of using the cloud for disaster recovery. What happens now?
It’s important to have a comprehensive and well-tested DR plan, and incorporate the cloud into it. Here’s how to put one together.
1) Audit your infrastructure and assess your risks
The first steps in creating a DR plan is to take inventory of your IT assets and assess the risks that might threaten them.
You should have a good idea of all the IT infrastructure that your company owns, how many of each piece of equipment you have, how much it’s all worth, and where it’s located.
Understand what applications access what data and how frequently, how much data you have, and where it’s all stored.
Then assess the potential risk to all of your assets.
Risks can come in different forms.
On-site risks include fires, power outages, cyberattacks, and more.
Natural disasters such as hurricanes, earthquakes, floods, and other calamities can impact entire geographical areas.
Less likely but even worse are regional or global events such as disease outbreaks, economic meltdowns, and terrorist attacks that can impact entire regions or nations.
Once you have a strong grasp of what assets might be at risk and what events might negatively impact your business, you can better design a DR plan to mitigate those risks.
2) Perform a Business Impact Analysis
The next step is to perform a business impact analysis. This will help you better understand the thresholds under which your business can operate after a disaster occurs.
There are two key parameters that your disaster recovery team has to determine:
- Recovery Time Objective (RTO)
- Recovery Point Objective (RPO)
Both of these parameters are extremely important in planning for what preparations are necessary to recover once disaster strikes.
Recovery Time Objective (RTO)
The RTO is the maximum acceptable length of time that your application can be offline before seriously impacting your business operations.
While downtime is always painful, it may impact certain companies more harshly than others.
For example, if your company is a hedge fund that runs a high-frequency stock trading platform, a disaster can bring your business to a halt. You can’t make a single trade while your software is down, and thus your company essentially ceases to operate.
In this case, you might set your RTO to be 15 minutes or less, and thus will have to invest heavily in your DR plan in order to achieve a full recovery in that short amount of time.
On the other hand, let’s say you run a co-working space. Your membership software is certainly important, but if disaster strikes, you can find workarounds such as having your members manually sign in when checking into one of your office locations.
Thus, your RTO might be set to one week. You won’t have to invest as many resources into disaster recovery because you’ll have ample time to acquire the backup assets that you need after the disaster strikes.
Understanding your RTO is very important because that length of time directly correlates to the amount of resources you need to invest into your disaster recovery plan.
Recovery Point Objective (RPO)
The RPO is defined as the maximum acceptable length of time during which data might be lost from your application due to a major incident.
To help determine your RPO, ask these two questions:
- How much data can I afford to lose if disaster strikes?
- How much time can elapse before all that data is lost?
The answer to #2 is your RPO.
RPO helps inform how often you should back up your data.
In the case of the high-frequency trading hedge fund, your RPO might be as little as 5 minutes because of the data-intensive and high-compliance nature of your business.
If you’re part of the co-working space company, your RPO might be on the order of days. It’s still important to back up your membership data but that data isn’t that time sensitive, so spending a lot of money on DR to meet a small RPO probably won’t be worth it.
For more information on RTO, RPO, and their differences, give these articles from Druva and Advisera a read.

3) Design your DR plan according to your RTO and RPO
Now that you know what assets to protect and what your RTO and RPO are, you can design a system to accommodate your DR goals.
Below are some approaches that you can implement for your DR plan. These aren’t mutually exclusive, and you can certainly combine some of these in order to achieve your RTO.
Backup and Restore
If you have a relatively long RTO and RPO, you can create a straightforward backup and restore DR plan.
This entails replicating your on-premise data in a cloud storage service like Amazon S3 or Azure Storage.
You’ll want to be sure that your cloud provider has a complimentary service that allows you to transfer your data into the cloud efficiently so you can access that data quickly.
Backup is only half of the process. If disaster strikes, you’ll also have to recover your data quickly to avoid prolonged downtime.
So be sure to understand the process you and your cloud provider will use to restore your data and systems as fast as necessary.
Pilot Light Approach
Ever wonder what the purpose of the pilot light in your heater is? Me neither.
Anyway, the pilot light is a small flame that always stays on and can immediately start up the heater to warm your home.
With respect to DR, the pilot light is a minimal version of your IT environment, running in the cloud, that can be immediately spun up in case of an emergency.
You can use the cloud to house the most critical elements of your application. If and when a disaster scenario rears its ugly head, you can quickly build around that core to fully restore your application.
The Pilot Light option allows you to recover your systems much more quickly than the Backup and Restore approach, since you’ll already have a core piece of your environment ready to roll at all times.
The extent to which to build out your Pilot Light infrastructure depends on your RTO.
Elements typically include replication of data in the cloud, pre-configured servers ready to be launched at a moment’s notice, and possibly storage of installation packages or configuration information. You may also want to set up additional database instances for data resiliency.
When the time comes for recovery, you can fire up your pre-configured cloud servers quickly, route your traffic to those servers, and scale them up as necessary.

Warm Standby
Warm Standby entails creating a scaled-down copy of your fully-functioning environment in the cloud.
This approach speeds up recovery even more because you’ll have a replica of your environment, albeit a contracted one, always running in the cloud.
You may set up a small number of low-capacity virtual servers and a few cloud databases where you mirror your on-premise data regularly.
In the event that your on-premise environment goes down, you can increase the capacity of your VMs, balance the load across them, and direct your traffic to them. You may also want to scale your databases to ensure your environment can handle the the increased load.

Full Replication in the Cloud
The approach that will allow you to recover most quickly is the full replication solution, where you have multiple environments actively running on-site and in the cloud.
In this case, you would completely replicate your on-premise environment in the cloud and distribute the traffic between the two environments.
If an emergency causes your on-premise environment to go offline, you can route all of your traffic to your cloud setup and scale appropriately.
While this approach will help you achieve a short RTO, it can be much costlier than aforementioned options, since your cloud environment will always be running. The cost will depend heavily on the amount of cloud infrastructure deployed and how much traffic is routed to it.
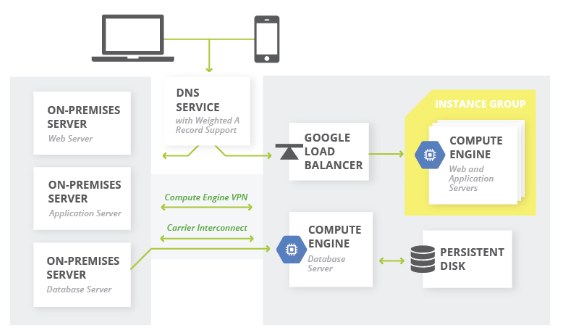
Multi-Cloud Option
If some or all of your environment is already in the cloud, it might make sense to use another cloud provider as your disaster recovery option.
Cloud providers certainly have methods for backup within their own environments, such as splitting their infrastructure into separate availability zones.
But no cloud provider is perfect, and downtime happens to everyone.
By using two different cloud providers, your infrastructure can be more resilient, since there are no dependencies between the services at all.
Going multi-cloud has its pros and cons though, so be sure it’s worth your while.
4) Select Your Cloud Provider
After you’ve mapped out the approach you need to take to meet your DR goals, the next step is to select a cloud provider that can help you get there.
If you have a long RTO and you’re using the Backup and Restore option, your decision might mostly come down to cost of storage and data transfer.
If you need some level of environment replication, you should consider a few other factors when assessing cloud providers, such as:
- Reliability
- Speed of recovery
- Usability
- Simplicity in setup and recovery
- Scalability
- Security and compliance
There are plenty of cloud DR companies for you to choose from.
The big cloud service providers like AWS, Microsoft Azure, Google Cloud, and IBM all have disaster recovery options.
There are also a bunch of smaller, lesser-known players who focus much of their efforts on providing quality Disaster Recovery as a Service (DRaaS). These companies include Sungard, BlueLock, iLand, and many others.
You should assess multiple cloud DR providers who can supply everything you need at a cost that fits your budget.
5) Set Up Your Cloud DR Infrastructure
Now that you have a cloud DR partner, you can work together to implement your design and set up your disaster recovery infrastructure.
There are a number of logistical issues to consider, the complexity of which will depend on the DR approach that you select.
How much of each infrastructure component will you need?
How will you copy your data to the cloud?
What’s the best way to implement user authentication and access management?
What security and compliance systems will you need to set up?
What control measures can you incorporate to minimize the likelihood of disaster events?
Your DR instance should be created to meet your RTO and RPO specifications to ensure that your technology will be up and running as soon as required after disaster strikes.
6) Document Your Recovery Plan
When an emergency occurs, you don’t want to leave any important tasks up to judgment. That’s why it’s imperative to document your recovery plan in the most detailed way possible.
Each member of your staff should know their exact role in deploying the cloud disaster recovery infrastructure.
Who is responsible for reaching out to the cloud provider contact? Who is in charge of running the deployment script? Who will route the web traffic to the cloud servers? Everyone needs to be crystal clear on what they’re responsible for.
Also, deployment instructions should be as specific and concrete as possible.
Tasks like “Route the traffic to the cloud servers” won’t cut it. Descriptive steps such as “Create an A record that points to the IP address 84.276.110.217” are much better.
A comprehensive, detailed document of your disaster recovery plan is critical to ensuring that your plan is executed properly when disaster strikes.
7) Test your plan regularly
Once your plan is created and documented, it’s important to test it regularly to ensure that there are no weak points.
While your plan might look great on paper, you need to execute it in the real world to find out how robust it really is.
Your first test will likely go terribly. Much of your staff won’t know what to do, processes won’t work, and communication will break down. It’ll be a mess.
That’s a good thing because you’ll be able to plug the leaks and be better prepared for when disaster really strikes.
The more complex your DR plan is, the more important it is to test it often.
Full DR tests should be run at least quarterly, and you can take weekly or daily snapshots of your backup infrastructure to ensure that it’s all running properly. Netflix actually developed a tool called Chaos Monkey that frequently introduces simulated failures into their AWS architecture so they can ensure that their disaster recovery plan is bulletproof.
There will always be changes in your organization that will make testing more important. Employees may come and go, roles may shift, and processes may be modified.
Testing your disaster recovery plan often will ensure you’re fully prepared for any emergency.
Conclusion
Disaster can strike at any time. Will you be ready to react quickly and efficiently?
A comprehensive disaster recovery plan will help you do so. And cloud computing can help you easily implement this plan to increase reliability and flexibility while saving time and money.
More and more businesses of all sizes are moving to the cloud for their disaster recovery, and it’s clear why.
Have you made the leap yet? What are your thoughts about leveraging the cloud for disaster recovery? We’d love to hear your insight in the comments.